Turning DeepSeek 3.2 into Real Work, Not a New Attack Surface
How to put DeepSeek 3.2 to work in production while managing model trust, open weights, data risk, behavioral risk, and deployment security.
Security, open weights, and what actually matters when you put it to work
DeepSeek 3.2 and 3.2 Speciale are in a very particular place in the AI landscape right now:
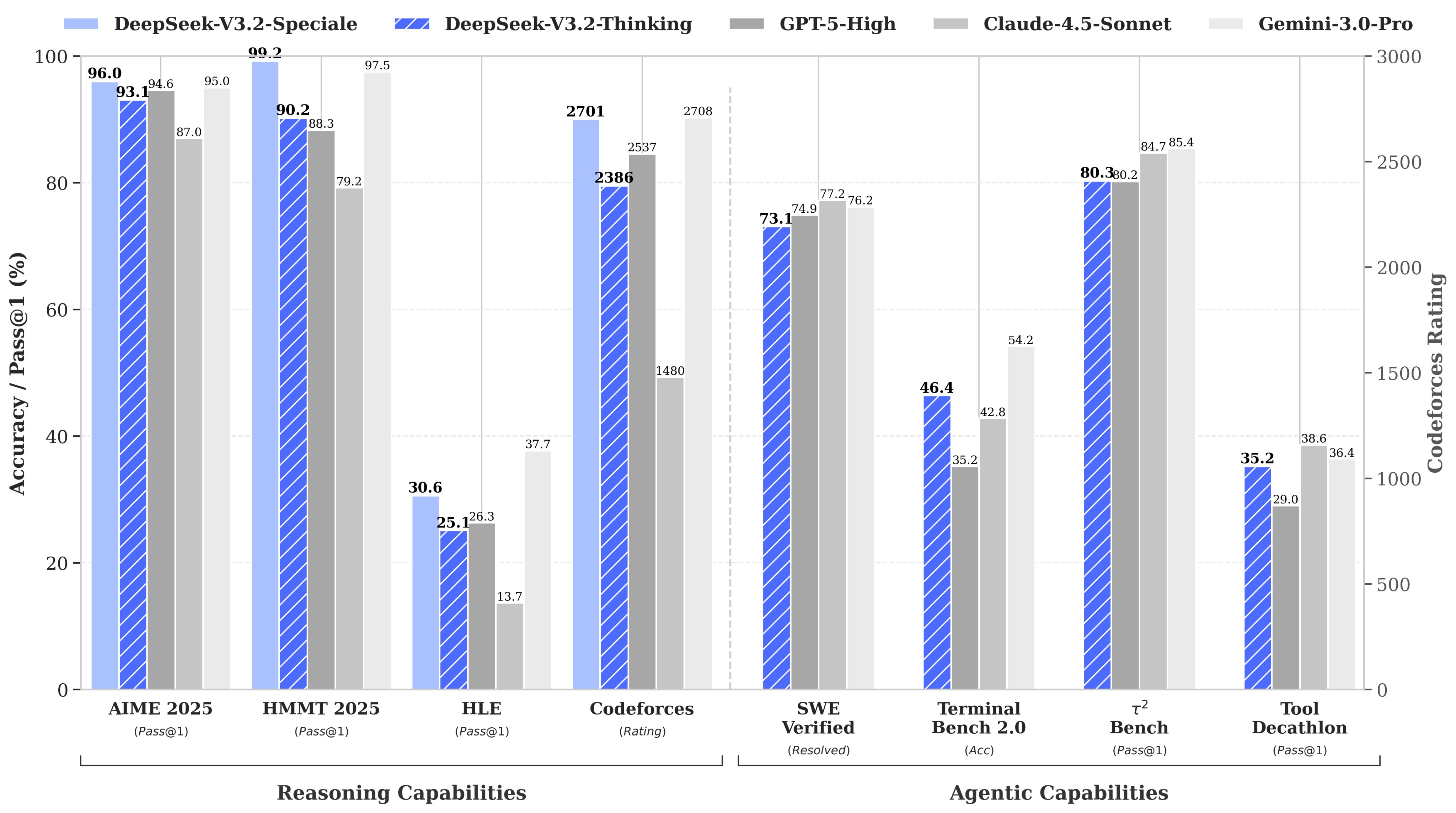
- On public benchmarks and third-party writeups, V3.2 is consistently described as frontier-tier for math, code, and reasoning—competitive with GPT-5-class models at a fraction of the cost.
- Both DeepSeek-V3.2 and DeepSeek-V3.2-Speciale are released as open weights under the MIT License, with full model files on Hugging Face that organizations can download and run themselves.
- First-party pricing puts V3.2 on the Pareto frontier for intelligence vs. cost, with input around $0.28 per million tokens and output around $0.42 per million tokens—far lower than typical GPT or Claude pricing. (For how to turn that cost advantage into real output, see How to Get 20–60x More Work Per Dollar.)
At the same time, regulators are treating it with caution:
- Italy's privacy watchdog (Garante) ordered DeepSeek to block its chatbot in Italy and had the app pulled from local app stores over unresolved questions about data use, where data is stored, and GDPR compliance. (Reuters, AP News)
- Australia banned DeepSeek from all federal government systems and devices, citing unspecified national-security and privacy concerns. (Reuters, The Guardian)
- Several U.S. federal agencies (including NASA, the Pentagon networks via DISA, and the Navy) and multiple U.S. states have restricted or banned the app on government-issued devices over data-security and espionage concerns. (Reuters)
None of this says "DeepSeek 3.2 is evil." It says that powerful systems that might handle sensitive data get scrutinized hard—whether they're from San Francisco or Shanghai.
The good news is that DeepSeek 3.2 is open weights. That gives you more control than you ever had with closed-source frontier models, if you use it correctly.
This post is about how to do that: how to use DeepSeek 3.2 in production without relying on blind trust, and without falling into lazy fear.
1. Model vs. App: Two Very Different Things
Most of the government and regulator actions so far have been about DeepSeek's consumer app and hosted cloud, not about the existence of the model weights.
Examples:
- Italy's Garante ordered DeepSeek to block Italian users and opened a privacy investigation after the company didn't adequately explain how it processes personal data, including questions about data residency in China.
- The same authority previously blocked ChatGPT in 2023 over GDPR concerns, then allowed it back after changes—so this is consistent enforcement, not a unique anti-China move.
- Australia's federal ban applies to DeepSeek on government devices and networks, not to private use, and is framed as a precaution around data and national security.
- U.S. agencies and states restricting DeepSeek emphasize the combination of sensitive government data and Chinese jurisdiction, not some secret vulnerability in the model itself.
That's one side of the story: hosted service risk.
On the other side you have:
…sitting under MIT, ready to be downloaded and run on your infrastructure.
Once you pull those weights down, "using DeepSeek" no longer has to mean "sending data to DeepSeek's cloud." The data path and the legal regime are now your choice.
That distinction—app vs. open model—is the basis for a more adult conversation about "trust."
2. Who Are You Actually Trusting?
When someone says, "We're using DeepSeek 3.2," that can mean very different things:
- DeepSeek's own app or API endpoint.
- A third-party inference platform running DeepSeek weights (e.g., a U.S. or EU cloud provider, or a router like OpenRouter using Western-hosted instances).
- A self-hosted deployment in your own VPC or data center.
Under the hood, three pieces matter:
- The model – the DeepSeek-V3.2 or V3.2-Speciale weights.
- The inference stack – vLLM / TensorRT-LLM / custom server, quantization, scheduling.
- The environment – hardware, network, logging, monitoring, policies, jurisdiction.
Open weights plus MIT licensing mean you're free to choose (2) and (3):
- You decide which country's law the infra lives under.
- You decide how logs are handled and who can see them.
- You decide whether inference happens in your own GPU cluster, a major U.S./EU cloud, or an external service with a specific contract.
With closed models, you're implicitly trusting:
This API provider will do the right thing with my data, and if they don't, I'll find out later.
With DeepSeek 3.2 as open weights, you have the option to flip that around:
This deployment I control will do what I configured it to do, and I'll verify that with my own tests.
That doesn't fix every problem, but it moves a lot of the risk into territory you can actually engineer.
3. "What If There's Something Hidden in the Weights?"
Even if you host DeepSeek 3.2 yourself, there's a fair question:
How do I know there isn't something sneaky baked into the model?
Realistic concerns include:
- Odd behavior on politically sensitive topics, aligned with Chinese content norms.
- Jailbreaks and prompt injection (not unique to DeepSeek; all LLMs suffer from this).
- Data leakage, where the model regurgitates training data or sensitive content more readily than you'd like.
You can't "read" a 70B-parameter model like source code. You can systematically probe it.
Garak: Red-Teaming the Model, Not the Marketing
Garak is an open-source LLM vulnerability scanner from NVIDIA's AI Red Team (GitHub).
At a high level, Garak:
- Sends structured probes to a model endpoint.
- Looks for prompt injection vulnerabilities, data leakage, jailbreaks, policy bypasses, hallucination, toxicity, and other failure modes.
- Produces reports that summarize where and how the model misbehaves.
If you:
- Download DeepSeek-V3.2 / V3.2-Speciale,
- Deploy it behind your own API, and
- Point Garak at that endpoint,
…you move from hand-waving about "can we trust China" to an actual graph of:
- Which attack patterns work.
- How that compares to GPT / Claude / other open models.
- Which mitigations reduce risk.
You don't get mathematical certainty. But you do get something much better than vibes: measured behavior on your deployment.
4. Data Risk vs. Behavioral Risk
DeepSeek 3.2 forces you to separate two different questions:
- Data risk – where does data go, and who can legally compel access?
- Behavioral risk – how does the model behave under normal and adversarial use?
Data risk
Regulatory actions so far are mostly about data:
- Italy's Garante blocked the app over lack of clarity around data usage and storage; Irish and French regulators have also requested detailed information on processing and data flows.
- Australia's ban on government devices is framed explicitly as a security and privacy move around the app's handling of data, not a blanket statement about open models.
- Reuters reports U.S. Commerce Department bureaus and multiple states (Virginia, Texas, New York, etc.) banning DeepSeek on government devices, again citing national-security and data-access risks.
Open weights give you a straightforward mitigation: don't send sensitive workloads to DeepSeek's own cloud.
Host the model:
- In a jurisdiction you're comfortable with (U.S., EU, etc.).
- Under your own logging, encryption, and retention rules.
- Behind your existing auth and network controls.
Behavioral risk
This is where Garak and similar tooling live:
- Can the model be jailbroken into generating things you don't want?
- Does it over-share information?
- How does it react to injection attempts?
Here, DeepSeek is just another powerful model:
- You should expect some failures.
- You should measure them.
- You should put application-level guardrails in front (filtering outputs, constraining actions, enforcing human review where needed).
When you combine:
- Self-hosting or trusted inference providers (to localize data risk), and
- Red-teaming + guardrails (to manage behavioral risk),
…"Can we trust DeepSeek 3.2?" becomes a question about your architecture, not their marketing copy.
5. Mapping DeepSeek 3.2 to Real-World Workloads
A reasonable way to think about DeepSeek 3.2 deployment is to bucket your use cases.
Bucket 1 – Low-risk / public data
Examples:
- Web research on public sites.
- Lead enrichment from public profiles.
- Drafting outreach and marketing copy you're comfortable publishing.
- Non-sensitive code refactoring.
Reasonable approach:
- Use a hosted DeepSeek endpoint you've vetted, or your own cloud deployment.
- Strip obvious PII before sending prompts.
- Log inputs/outputs sensibly.
- Rate-limit and monitor usage.
Bucket 2 – Medium-risk / internal, non-regulated data
Examples:
- Summarizing internal docs that don't contain regulated PII.
- Internal ops tooling and reporting.
- Sales/revops automation where errors are manageable but annoying.
Reasonable approach:
- Self-host DeepSeek 3.2 (or run it in a tightly controlled cloud environment).
- Put it behind your own API gateway, auth/identity policies, and network segmentation.
- Use Garak to regularly probe the deployment and track changes over time.
Bucket 3 – High-risk / regulated or crown-jewel workloads
Examples:
- Trade secrets and unreleased IP.
- Highly regulated personal data (finance, health, education, etc.).
- Safety-critical or mission-critical decisions.
Reasonable approach:
- Self-hosted DeepSeek V3.2 on strongly-controlled or air-gapped infra, or alternative open-weights models if policy requires, or Western frontier APIs where contractual and compliance comfort is higher.
- Strong egress controls and sandboxing.
- Application-level constraints and validators.
- Human-in-the-loop for irreversible actions.
- Ongoing red-teaming and monitoring.
The pattern here isn't "China bad, West good." It's:
Powerful models + sensitive data = serious engineering, no matter the flag on the logo.
DeepSeek 3.2 just happens to hit a spot on the cost/performance curve where doing that engineering work is worth it.
6. Where Gobii Fits In
Gobii is an open-core AI workforce platform. Our job is to take models like DeepSeek 3.2 and turn them into browser-native workers that:
- Log into CRMs, ATSs, and SaaS tools.
- Scrape, enrich, and update records.
- Run prospecting, recruiting, ops, and research workflows end-to-end.
How we use DeepSeek 3.2 reflects everything above:
- It's a first-class option for high-volume, cost-sensitive work where the data profile fits.
- GPT- and Claude-class models remain available for higher-risk decisions or customers with specific regional or vendor preferences.
- Each worker in Gobii can have its own model policy, so you can mix and match: "cheap and strong" (DeepSeek 3.2) for most steps, "premium and conservative" (GPT/Claude) for others, or "fully self-hosted" for specific tenants or workflows.
The agent layer is open-core and self-hostable, so you're not relying solely on our infra or anyone else's. You can:
- Run the Gobii stack in your own environment.
- Connect it to your own DeepSeek deployment (or other models).
- Integrate your own logging, policy, and compliance workflows.
This isn't hypothetical. When DeepSeek V3.2 launched, Gobii integrated it immediately—and within days became the #1 application by usage on OpenRouter for that model (we wrote about it here). Teams that care about turning DeepSeek into real work are already running it through Gobii.
On the security side, we treat LLMs like any other exposed system:
- Use tools like Garak to probe model deployments.
- Add application-layer guardrails around actions (not just text).
- Reserve human review for steps where your risk model says "don't fully automate this yet."
DeepSeek 3.2 is a very strong model. Gobii is the layer that makes sure strength shows up as useful work, not unmanaged risk.
7. So… Can You Trust DeepSeek 3.2?
Not in the sense of "paste anything into any random app and hope."
But in the sense that matters:
- Yes, you can make DeepSeek 3.2 a rational part of a secure, global-scale AI stack—if you control where it runs, measure how it behaves, scope it to workloads that match its risk profile, and keep other models in your portfolio for the cases where it isn't the right fit.
DeepSeek 3.2 and 3.2 Speciale are clearly important milestones: open, strong, cheap. The security story isn't "never touch it." It's:
Use it where it makes sense, under conditions you actually understand.
That's the level of pragmatism you want if you're trying to build something valuable in a world where the best models can come from anywhere.
References
- DeepSeek-V3.2 on Hugging Face
- DeepSeek-V3.2-Speciale on Hugging Face
- Introl – "DeepSeek V3.2: Open Source AI Matches GPT-5 and Gemini at Fraction of the Cost"
- Reuters – "Italy's privacy watchdog blocks Chinese AI app DeepSeek"
- AP News – "Italy blocks access to the Chinese AI application DeepSeek to protect users' data"
- The Guardian – "DeepSeek banned from Australian government devices amid national security concerns"
- Reuters – "Australia bans DeepSeek on government devices citing security concerns"
- Reuters – "US Commerce department bureaus ban China's DeepSeek on government devices"
- Garak – open-source LLM vulnerability scanner (GitHub)